Introduction
It wasn’t that long ago we were all struggling to answer a basic question: what is the cloud? The early cloud was a jumble of established tech giants and startups, with Amazon on one end of the spectrum - pushing low-level storage, compute and network services - and Microsoft / Salesforce on the other end of the spectrum - pushing development and deployment platforms like Force.com and Azure. The confusion was further exacerbated by a host of startups with very different offerings (e.g. Aptana, Heroku, Engine Yard), and numerous old school companies attempting to rebrand their distinctly non-cloud products in the cloud.
But over time the market forces converged us toward a common definition that I like to call Cloud 1.0. While Amazon was the de facto creator of Cloud 1.0, it was followed quickly by Rackspace, some tier 2 providers, and eventually by IBM, HP and finally and begrudgingly, Microsoft.
The features of Cloud 1.0 include:
- On-demand compute with support for different configurations, including operating system, processing power, memory and I/O.
- Highly performant, fault-tolerant, durable, and eventually consistent object store.
- Support for multiple regions and data centers around the globe.
- Support for consumption-based pricing.
- Ability to control security of resources.
- On-demand network services, e.g. CDN, DNS, and VPC.
- Ability to provision, deprovision and access resources via an API, console, and command line.
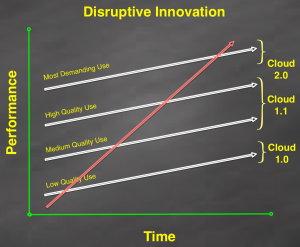
While Cloud 1.0 was innovative and disruptive, from the perspective of Clayton Christensen’s disruptive innovation curve (see graphic to right), it provided support for only the low quality uses of infrastructure - e.g. basic web applications. But it found its early niche in a market underserved by hardware / service providers: startups needing rapid access to on-demand, consumption-based infrastructure.
Cloud 1.1
The most critical deficiency in Cloud 1.0 that prevented the migration of workloads into the cloud was the lack of attached storage. While Amazon’s Elastic Block Storage (EBS) has always been a much maligned service for Amazon, the existence of EBS was critical to the adoption of AWS. Not only did EBS enable the ability to dynamically attached disks of variable size to servers, but users quickly found they could manipulate them like physical disks (e.g. mirroring, striping, and so on), enabling new workloads to move into AWS.
In addition, starting as early as 2009, Amazon introduced services like DynamoDB, Amazon Relational Database (RDS), and ElastiCache. These services provided basic application building blocks that enabled the development and deployment of new software applications that leveraged the compute, storage and network services on Cloud 1.0. These services were typically just fully managed / on-demand versions of popular commercial and open source applications in the marketplace.
The features of Cloud 1.1 include:
- Provisioning & attaching durable storage to compute with variable sizes and consistent I/O performance.
- On-demand application services, e.g. relational databases, NoSQL databases, distributed memory cache.
- Increased breadth of compute and storage to enable support for more workloads, e.g. high IOPS, high memory and high CPU workloads.
From the perspective of the disruptive innovation curve, Cloud 1.1 provided support for the medium and high quality uses of infrastructure - e.g. SaaS business services.
Cloud 2.0
At Amazon re:Invent this year, I couldn’t help but to think I was seeing the beginning of Cloud 2.0: the delivery of new, complex and fully managed application-level services built upon IaaS. At first glance it looked like what Microsoft and Salesforce had evangelized back in 2008-10: a platform to enabled the rapid development and deployment of scalable new applications. But on closer inspection, instead of delivering an integrated platform for the development and deployment of applications, it provides vertical point services that solve complex business problems (e.g. data warehousing, data analytics, video streaming). These services can be used with or without IaaS or PaaS services, and can even be used as extensions to private or hybrid clouds.
Another advantage to Amazon's envisioning of Cloud 2.0 is that its layering on top of IaaS has created a virtuous cycle. AWS is leveraging their optimized infrastructure to deliver IaaS services (e.g. EC2, EBS), then using this same IaaS infrastructure to develop and deliver higher level / margin platform services (e.g. Kinesis, AppStream), which in turn are driving additional innovation back into the IaaS services (e.g. C3 and I2 instance type families).
I am defining Cloud 2.0 as:
- Standalone, fully managed, high value / high margin point services that solve specific business problems.
- Delivered on-demand and priced based on consumption.
- Deliver solutions to problems previously requiring the deployment and operation of multiple integrated functional clusters.
- Accessible through API.
- Built on top of IaaS.
2014 and Beyond
If Cloud 2.0 is in fact the future of cloud computing, it will not be without its downsides. In exchange for rapid application development, decreased operational costs, and increased agility, will come increased vendor lock-in, new challenges in portability, and a higher complexity to predicting / managing costs. It may also result in a further separation in cloud vendors, as the software innovation required to build and sustain a virtuous IaaS / PaaS cycle become feasible only for the most innovative cloud providers.
Regardless of your opinions on the evolution of the cloud, there has without a doubt been a tremor in the cloud computing force, whose impact will become clearer as 2014 unfolds.
Related posts: A Cloud Management Taxonomy, 10 Immutable Laws of Cloud Computing, Which Cloud Sits at the Cool Kids' Table